Serverless Testing, Part 2: SOLID Architecture for Lambda

AWS Serverless Community Builder, Serverless Architect and Evangelist, creator of serverlessdna.com
Serverless Testing, Part 1: What I forgot at the beginning describes the start of my serverless story where I forget about plain old Software Engineering Principles, and I re-introduced the Dependency Inversion Principle, which is essential when writing software! I want to explore software architecture for serverless functions in this second instalment. You will learn about SOLID principles and we will break down Hexagonal Architectures and how these ideas work together to simplify building Serverless code.
In my experience, many teams who are moving into Serverless development are from a heavy infrastructure background and are less experienced in application development using software architecture principles. So I like to start by going back to basics and talking about SOLID principles of building software.
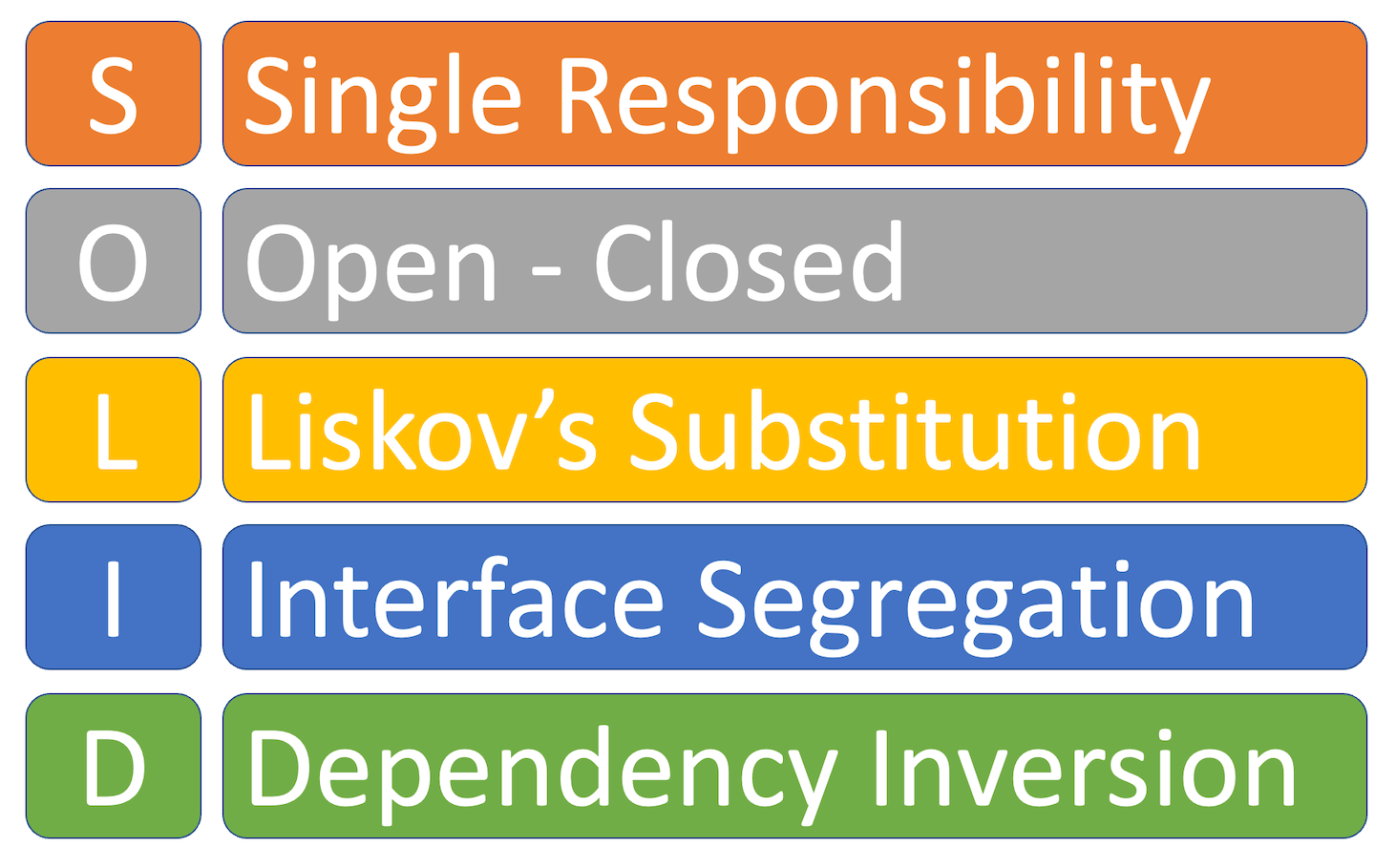
Single Responsibility Principle
A function should have one reason to change
Functions should have a single responsibility which is the only reason it should change. The more responsibilities your code has, the more reasons you will have to change it, and the more complex your functions will become over time. Keeping functions simple has several key advantages - it lowers code maintenance costs and makes them faster to execute. However, keeping functions simple is not as easy as it sounds and is part of the distributed design that causes friction in some teams who feel that serverless systems are complex to build or have too many moving parts. This aspect of serverless is the hardest to deal with and needs a disciplined approach to keeping your solutions simple.
Open / Closed Principle
Software entities (classes, modules, functions, etc.) should be open for extension but closed for modification.
This software principle means that classes should be open for extension but closed for modification meaning the inner working of a class or function should not need changing when a dependent object or class changes. You can achieve this through interfaces that extend your code's inner working by introducing a new implementation. Using interfaces in this way enhances the loose coupling of dependencies.
I also like to apply this to serverless functions when you need to write code. I always try and make my functions data-driven and configurable so that the processing relies on only the event triggering the function. This principle applied to serverless is about not changing your original service to deal with specific behaviour in a specialised context. Instead, look to make these exceptional cases an option or feature flag and encourage composability to add additional processing.
Liskov's Substitution Principle
Overridden class methods must have the same input parameters as their superclass. So, if it looks like a duck and behaves like a duck, it is a duck, and if you want a new duck, make sure it quacks the same as all the others.
Liskov's principle states that if you use a subclass in place of its parent class anywhere in your software, nothing will break. In simple terms, parent classes define a contract that sub-classes should never alter - violating this principle means clients who try to use this sub-class will no longer work as expected without being modified.
In serverless, a new version of your service should always be able to replace a previous version without breaking anything. This also puts our design focus on service consumers or customers who do not need to change their code when a new version is deployed, which would be considered a breaking change for the Interface.
Interface Segregation Principle
No code should be forced to depend on methods it does not use
The Interface Segregation principle keeps your defined interfaces simple and specific to their purpose. Keeping interfaces clean is essential; otherwise, every implementation is forced to implement functions rarely used, which is a waste of effort and increases software complexity.
This principle also helps in serverless designs by ensuring that we design simple, single-purpose interfaces for our services. A service that does too much will expose too many details and may leak internal implementation details to consumers, which is always a mistake for any microservice architecture. Keeping interfaces simple and to the point is what this principle is about, and we should be strong in applying it to every service boundary we design.
Dependency Inversion Principle
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
Dependency Inversion is all about creating functional abstractions between different layers of our code. This principle enforces the use of interfaces for every dependency, enabling the simple replacement of any component in our code quickly and easily. To embrace this principle means when designing an interaction between a high-level module and a lower level, one should be created with the interactions in mind, which will dictate the overall interface design. In this way, the coupling of our software components is reduced, and we can introduce new implementations at any time, which is ideal when we have embraced all the SOLID principles explained here.
The serverless use-case for this principle is really in building out strong software domain abstractions around cloud services to isolate business logic from the complexity of the cloud services it uses. This was the main point I introduced in Part 1 of this series.
Hexagonal Software Architecture
Hexagonal Architecture is all the rage in the Serverless world and has been written about by many people:
Ready for changes with Hexagonal Architecture on the Netflix TechBlog by Damir Svrtan and Sergii Makagon
Developing evolutionary architecture with AWS Lambda on the AWS Blog by Luca Mezzalira
Service Ports: Finding a Loosely Coupled Utopia with Event-Driven Serverless on Serverless Transformations by Ben Ellerby
These articles describe the benefits and tell you why you should be using hexagonal architecture. They all talk about Ports and Adapters as the magic you need to isolate your business domain logic from the more specific lower-level code that deals with writing data to databases, file systems or API interfaces. I don't like to use "hexagonal" or "ports". Instead, I prefer to talk about software patterns.
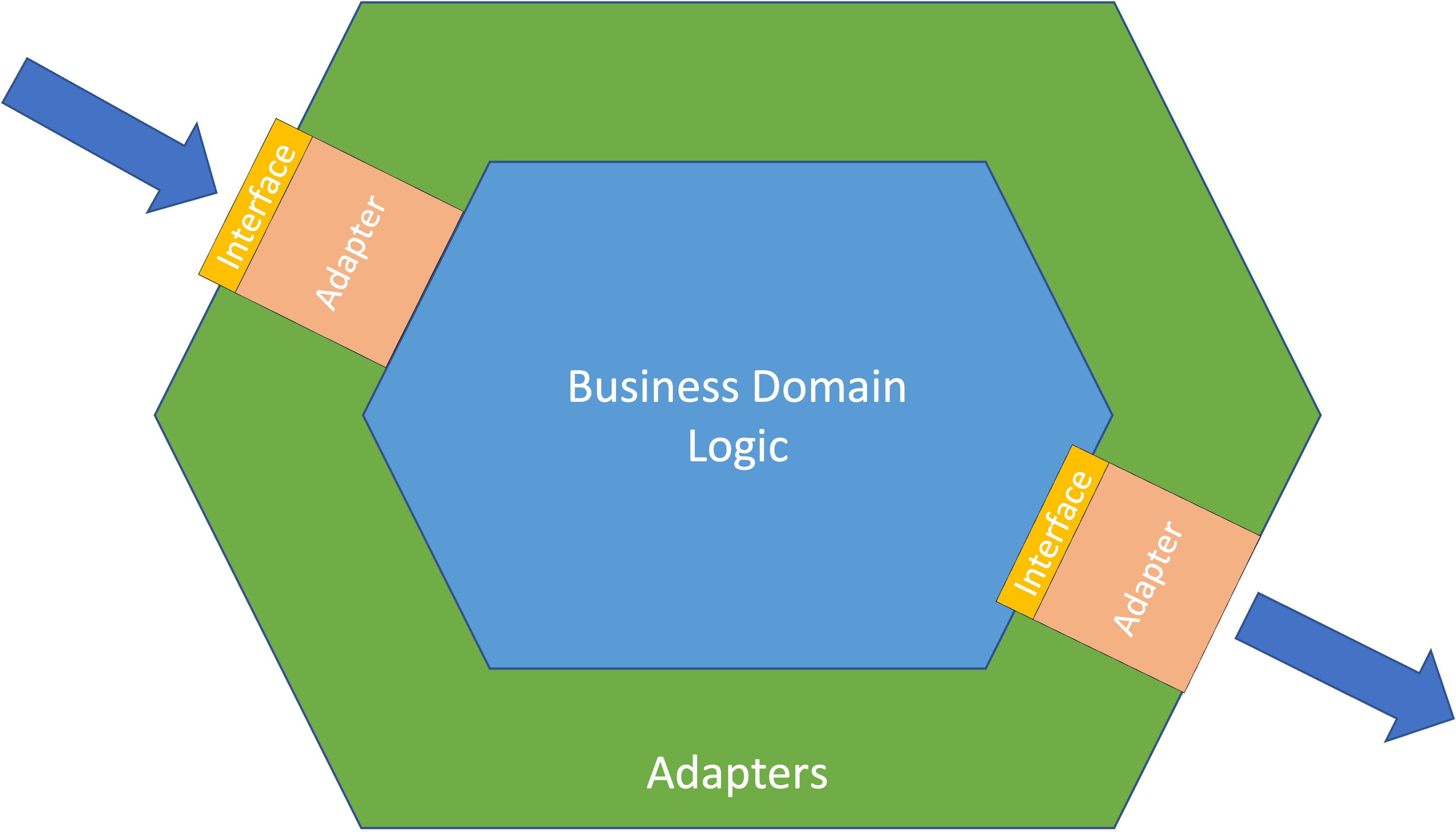
Building your software using this concept is nothing more than embracing the Dependency Inversion Principle from the SOLID principles we have already discussed. In hexagonal architectures, Ports are nothing more than well-defined Interfaces clearly defining your business domain interactions with external dependencies. Adapters are specific implementations of these business domain interfaces (Ports) to enable the de-coupling of your business domain logic from the cloud environment you deploy to. Adding dependency injection into the mix at this point is the real magic; Enabling injection of Adapters into your business domain logic allows a lot of freedom in building and testing your code.
I strongly feel there is a lot of effort focused on developers mocking SDK elements of AWS and other cloud providers. A lot of time is wasted trying to work out how to mock SDK responses from SDK API calls. By adopting business domain Interfaces and implementing them with Adapters, you can instantly create mocks using a mock implementation of the Interface for local testing purposes. This means your business domain developers do not need to know about the AWS SDK dependencies. This can be locked away within the Adapter implementations, which can be handled by framework developers who can be specialists for your cloud environment. Combining Adapters with simple dependency injection allows your adapter dependencies to be injected, meaning business domain code does not need to change whether you are unit testing, integration testing, or deploying to the cloud. You will have adapters for each of these environments and can drive the injection of these dependencies when needed so all your business domain logic can be quickly and simply unit tested.
A huge benefit of adopting a Hexagonal architecture is to isolate your business logic from your cloud and serverless components that make up your application. This means you can now have some separation of responsibilities within your team - Experts on your cloud integration and experts on your business domain logic. With this isolation, you can have less cloud experienced programmers focus on business logic and more deeply cloud experienced developers on Cloud integration - this separation of concerns is powerful.
The Road to Hexagonal Applications - Service Oriented Architecture (SOA)
Clean hexagonal architecture comes down to software engineering principles we have discussed throughout this article, and I will throw in one more term - Service Oriented Architecture (SOA). Wrapping our business domain logic into Service classes creates a complete separation between your cloud environment and application logic; it also becomes a natural break between cloud expert developers and business domain developers - something I have been searching for to create layered teams with specific skill-sets across cloud and the business domain.
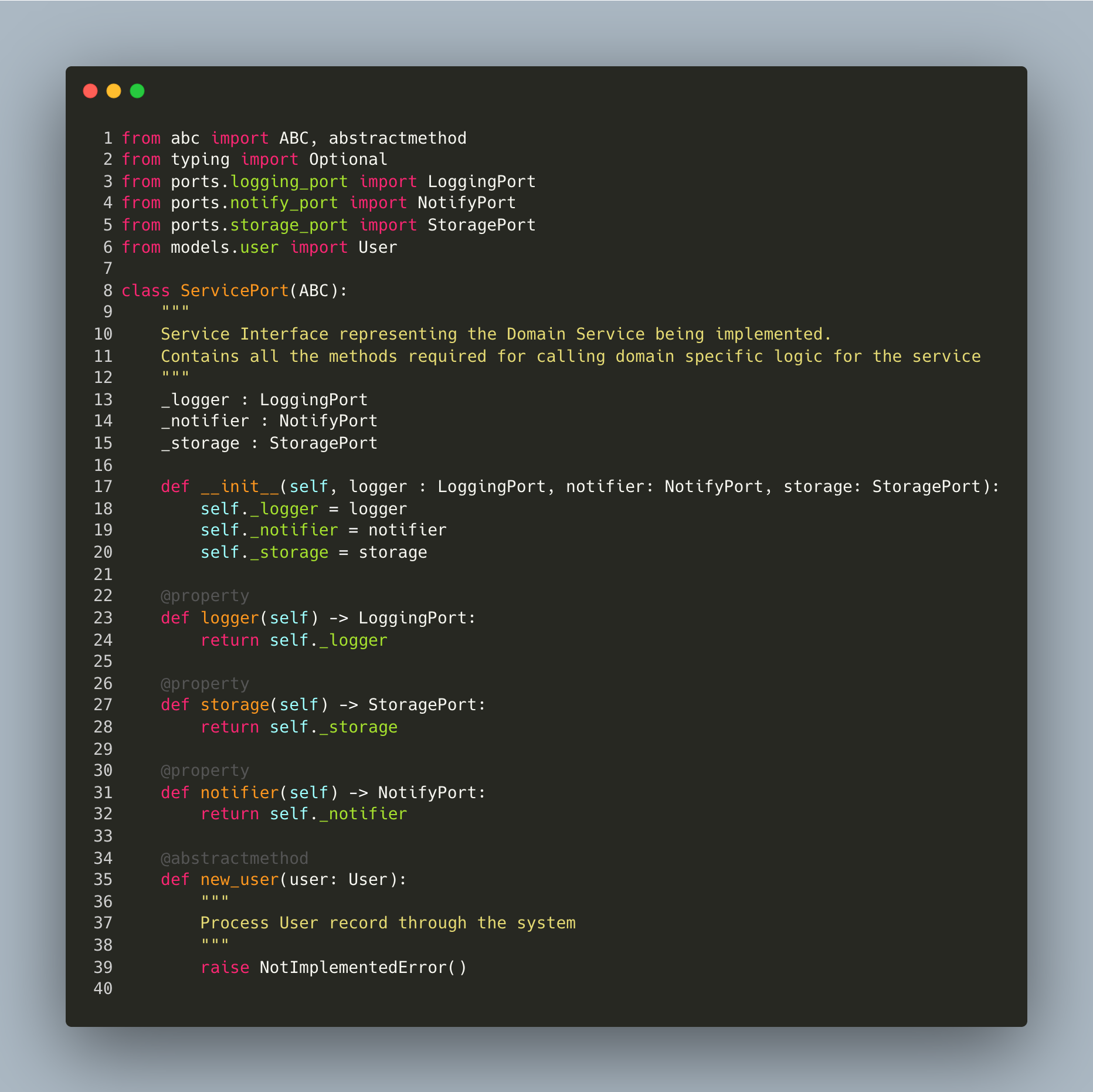
Using Services as the core base also allows direct and straightforward dependency injection of the various dependent interface adapters (Ports) required for the service to function. The following code snippet shows an example of a base abstract style python class for a Service Interface (Port). It accepts several other adapters for core functionality required, including Logging, Notifications and Storage. Through dependency injection for domain adapters - the business domain logic is now wholly isolated via the Dependency Inversion Principle I mentioned earlier.
Adding Business Functional Adapters (Ports)
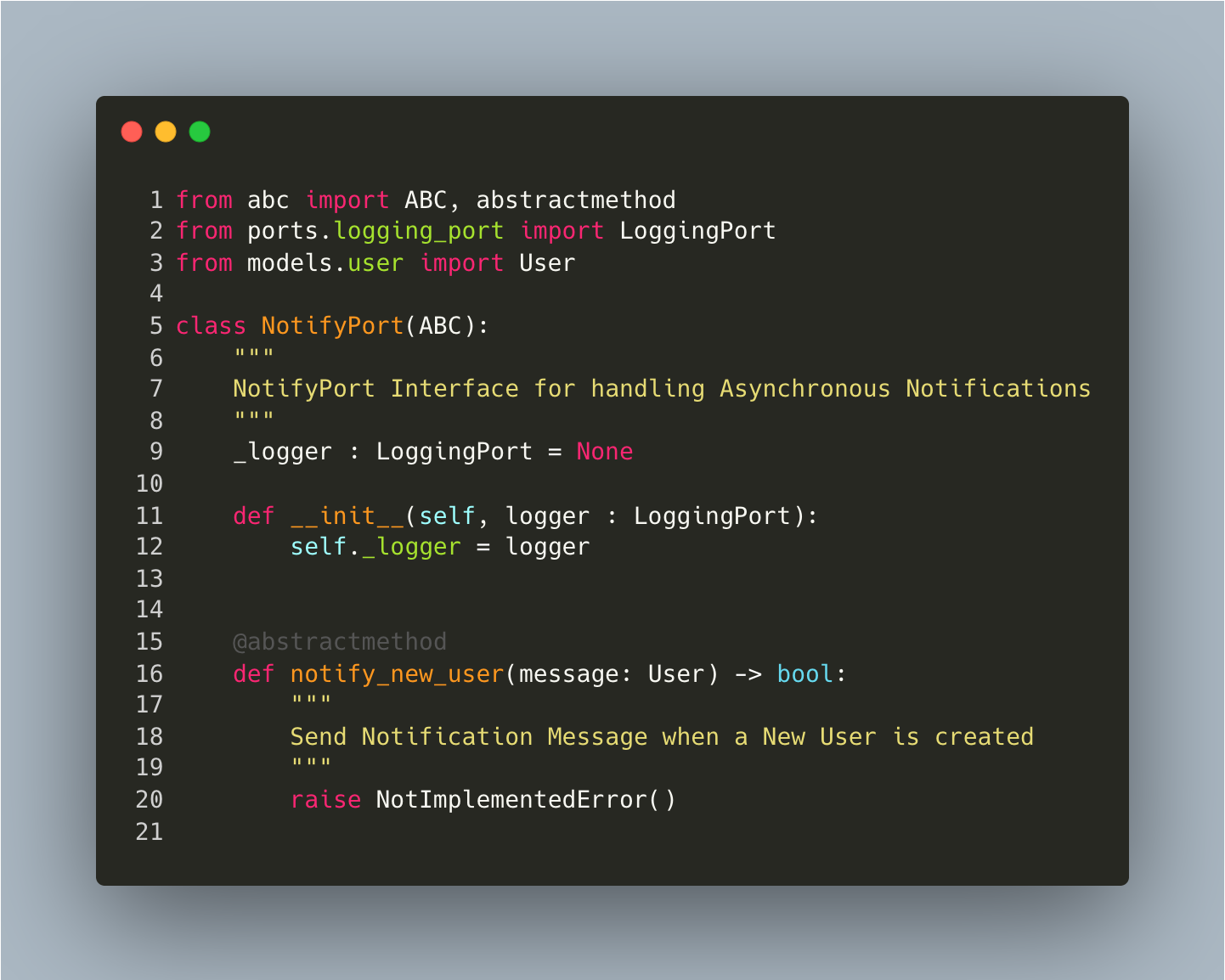
In the Service example, several adapters are injected as dependencies. The following code sample shows how you can structure the notification adapter (Port), which has a business-focused method notify_new_user that is functional. In this way, we separate the detail of the notification implementation from our domain programmers. This also means we can pivot the actual implementation without changing business domain code - so from a SOLID perspective, we are now embracing the Open-Closed Principle and the Dependency Inversion Principle - two powerful software engineering techniques.
Bringing it all together
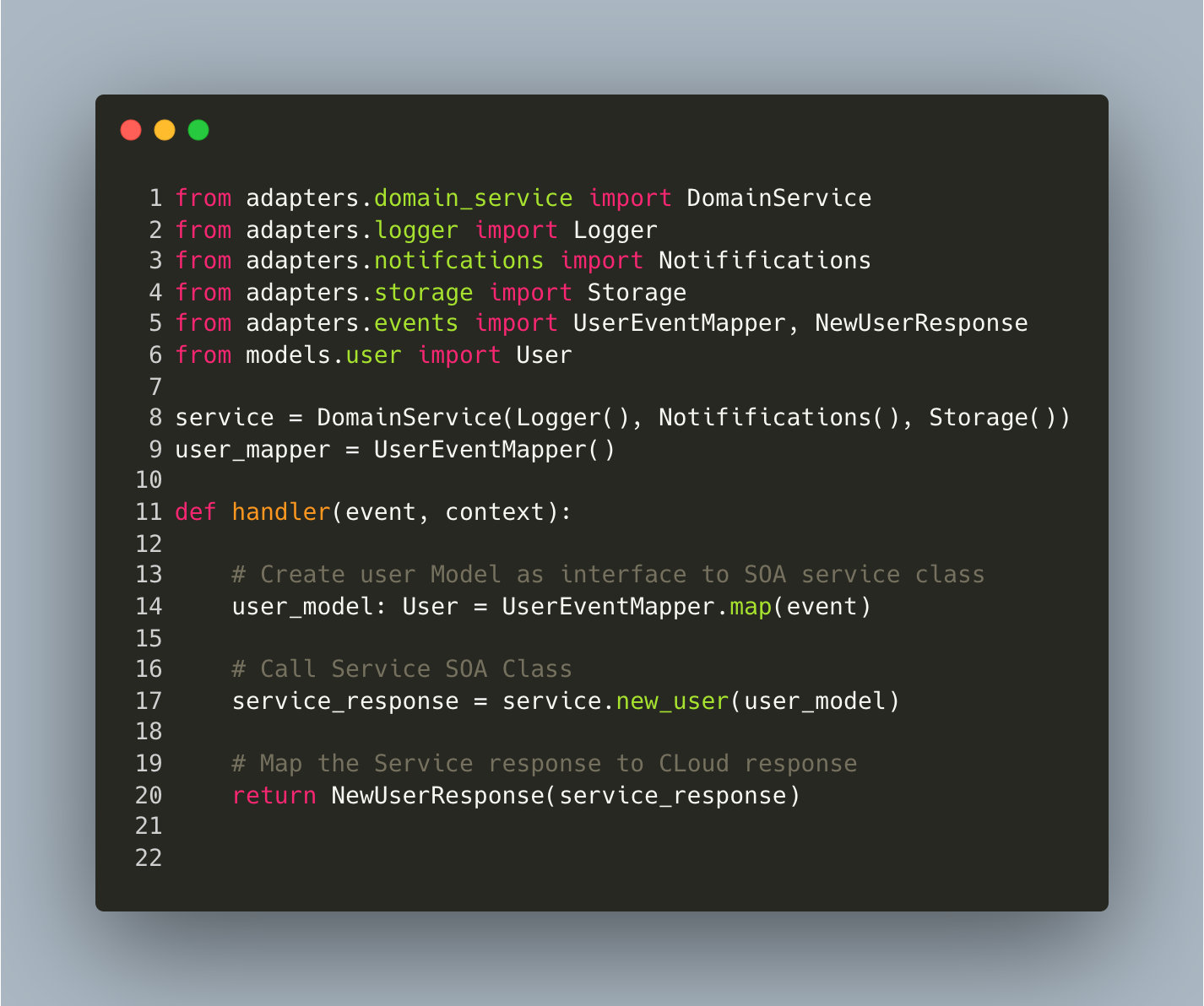
The following example shows how an AWS Lambda handler would apply the techniques discussed in this article. An adapter class (UserEventMapper) translates the Lambda event into a User model, which can be passed into the Service instance to process the new_user. The Service response is also mapped by an adapter class (NewUserResponse) to enable an actual AWS Lambda Service response based on the service used to trigger this function. This creates a very clear Lambda function that anyone can look at and understand what is happening. The adapter classes used can have their implementations changed to alter how this function is being triggered—all without making changes to the business domain logic.
We have explored the core of software engineering - SOLID principles, Dependency Inversion, Dependency Injection and Service-Oriented Architecture (SOA). Combining these techniques can assist in simplifying your development team's journey to Serverless by abstracting away the cloud complexity that Serverless developers are traditionally confronted with. Using these techniques discussed here, we can reduce the cognitive load developers have to contend with in creating serverless solutions. This all does feel like it goes against the simplicity of serverless, but we must acknowledge that we are mostly building software solutions at the end of the day. I say mostly as we should be embracing serverless services where possible, but like Jared Short says - "When you write Serverless code, you need to own it", so engineer it properly and take control.
Own it is what I say. Own it with SOLID principles, Interfaces and Adapters and Service-Oriented Architecture.




