Serverless Testing, Part 1: What I forgot at the beginning

AWS Serverless Community Builder, Serverless Architect and Evangelist, creator of serverlessdna.com
This is the first in a series of articles about Serverless software architecture and testing. I am collating a summary of what I have learned on my journey to Serverless and am starting with this introduction, highlighting my thoughts on what I forgot when I started learning about serverless. This series will be made up of three parts:
Part 1: What I forgot at the beginning
Part 2: SOLID Architecture for Lambda
Part 3: Simplify Testing with SOLID Architecture
Serverless Testing has been a hot topic in recent times. Many of the articles focus on general approaches, tooling to automate the creation of temporary stacks, and tell us to stop emulating the cloud locally and test in the cloud! In this article, I won't be covering these tools and approaches. Instead, I want to focus on what I forgot on my Serverless journey, and hopefully, it will help you not make the same mistake.
I started my journey with Serverless over four years ago when Lambda was relatively new, and we were all trying to work out just how this new cloud technology worked, scaled and could be used to create real, working, resilient solutions. There are many things to learn about at first - Lambda, SQS, SNS, DynamoDB, and the list goes on. So many new things that we all get wrapped up in learning how these products work.
When I started building serverless, I started with simple code; they were just functions, after all. Then, I quickly moved to local emulation of SQS, SNS, etc., to do what we have always been encouraged as software engineers - do end-to-end local testing. With mixed success, I moved back to unit testing with event fixtures to test my core business logic and continued to refine my testing knowledge and skills. There are always complexities involved with testing lambda code; There are interactions with cloud managed services such as S3, SNS, SQS or DynamoDB, which have AWS SDK clients to manipulate data being stored or processed. Now I spent a lot of time working out how to mock these AWS dependencies in my unit tests and make sure the SDK calls expected were made. Every new service seemed to introduce a new challenge; I spent more time writing mocks and getting unit tests working in this foreign land of AWS dependencies than building solutions and started to feel less productive. I have spent a lot of time the past few months reflecting on my journey since it began and how I have changed my thinking in many areas, particularly around testing serverless solutions.
I strongly feel I got wrapped up in the details of all the new services I had to deal with and coming to terms with how they all worked. The cognitive load on putting this all together at first is a lot! Combining this additional learning and the understanding that we are just writing functions means we expect to be writing fewer lines and simpler code. I was doing just this when I first started and looking back. I can see what I forgot about! I forgot all about plain old Software Engineering!
As a professional Software Engineer with a lot of experience, this is quite a confronting revelation. However, looking at conversations within the community over the past year, I feel I am not alone here. So what do I mean when I say I forgot about plain old Software Engineering? Three small words come to mind - Dependency Inversion Principle.
Dependency Inversion Principle
This core principle of Object-Oriented design sounds scarier and more confusing than it is. The following describes this design principle defined by Robert C. Martin:
- High-level modules should not import anything from low-level modules. Both should depend on abstractions (e.g., interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
Dependency Inversion is all about creating functional abstractions between different layers of our code. In a Serverless function context, this technique allows us to focus on more meaningful, descriptive functions to perform actions for our code rather than getting bogged down in the detail of an AWS SDK client for DynamoDB and its associated API calls. Creating these abstractions also removes the implementation detail and complexity of the cloud service mocking of the past. It allows quick and clean testing of each Interface since we can introduce a test stand-in implementation for any abstraction.
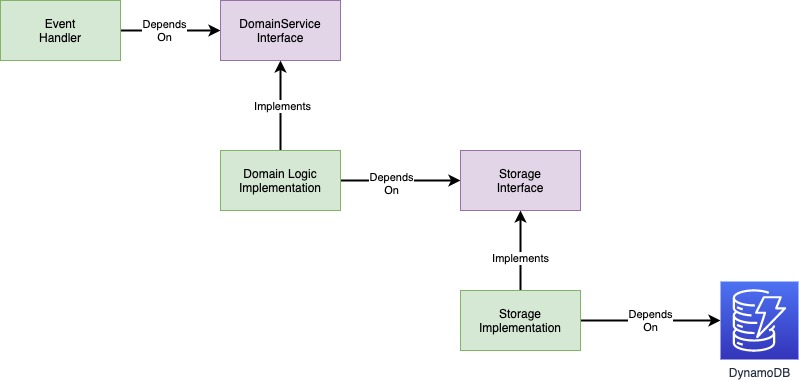
Class Diagram - Dependency inversion applied to Lambda handler
So what we need to look at is creating functional abstractions for any call from our core business logic out to the cloud. For example, in the diagram above, you can see the EventHandler depends on the DomainServiceInterface and the DomainLogicImplementation, which implements the DomainServiceInterface, depends on the StorageInterface. This allows the replacement of any green implementation blocks with Testing Stubs enabling all the components to be tested without creating complex mocks and test assertions. This simple software engineering principle is what I forgot about during the start of my Serverless journey. With the state of confusion and commentary around Serverless testing recently, I felt compelled to share my thoughts and what I forgot about when I first started. Hopefully, this will help you find your way quicker in this often-confusing space.
This article is the first in a new series I am writing on Serverless Software Architecture and Testing. These concepts go hand in hand as good architecture and code organisation naturally lead to better testing. My next article will be about SOLID Architectures for Lambda, taking the Dependency Inversion principle mentioned above further and deeper.




